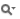15 if ((p_c & mask_tab[cnt])==val_tab[cnt])
break;
16 if (++cnt>=6)
return 0;
28 return utf8[0]>0 ? 1 : 0;
37 if ((*utf8&mask_tab[cnt])==val_tab[cnt])
break;
38 if (++cnt>=max)
return 0;
42 if (cnt==2 && !(*utf8&0x1E))
return 0;
47 res=(0xFF>>(cnt+1))&*utf8;
51 if ((utf8[n]&0xC0) != 0x80)
53 if (!res && n==2 && !((utf8[n]&0x7F) >> (7 - cnt)))
56 res=(res<<6)|(utf8[n]&0x3F);
75 return utf8[0]>0 ? 1 : 0;
85 if ((*utf8&mask_tab[cnt])==val_tab[cnt])
break;
86 if (++cnt>=max)
return 0;
90 if (cnt==2 && !(*utf8&0x1E))
return 0;
95 res=(0xFF>>(cnt+1))&*utf8;
99 if ((utf8[n]&0xC0) != 0x80)
101 if (!res && n==2 && !((utf8[n]&0x7F) >> (7 - cnt)))
104 res=(res<<6)|(utf8[n]&0x3F);
119 else if (wide < 0x800)
121 else if (wide < 0x10000)
123 else if (wide < 0x200000)
125 else if (wide < 0x4000000)
127 else if (wide <= 0x7FFFFFFF)
139 target[5] = 0x80 | (wide & 0x3F);
143 target[4] = 0x80 | (wide & 0x3F);
147 target[3] = 0x80 | (wide & 0x3F);
151 target[2] = 0x80 | (wide & 0x3F);
155 target[1] = 0x80 | (wide & 0x3F);
167 if (cur_wchar < 0x10000) {
168 *out = (char16_t) cur_wchar;
return 1;
169 }
else if (cur_wchar < (1 << 20)) {
170 unsigned c = cur_wchar - 0x10000;
173 out[0] = (char16_t)(0xD800 | (0x3FF & (c>>10)) );
174 out[1] = (char16_t)(0xDC00 | (0x3FF & c) ) ;
177 *out =
'?';
return 1;
182 if (p_source_length == 0) {*p_out = 0;
return 0; }
183 else if (p_source_length == 1) {
184 *p_out = p_source[0];
188 unsigned decoded = p_source[0];
192 if ((decoded & 0xFC00) == 0xD800)
194 unsigned low = p_source[1];
195 if ((low & 0xFC00) == 0xDC00)
197 decoded = 0x10000 + ( ((decoded & 0x3FF) << 10) | (low & 0x3FF) );
208 PFC_STATIC_ASSERT(
sizeof(
wchar_t) ==
sizeof(char16_t) );
212 PFC_STATIC_ASSERT(
sizeof(
wchar_t) ==
sizeof(char16_t) );
218 PFC_STATIC_ASSERT(
sizeof(
wchar_t ) ==
sizeof( char16_t ) ||
sizeof(
wchar_t ) ==
sizeof(
unsigned ) );
219 if (
sizeof(
wchar_t ) ==
sizeof( char16_t ) ) {
220 return utf16_decode_char( reinterpret_cast< const char16_t *>(p_source), p_out, p_source_length );
222 if (p_source_length == 0) { * p_out = 0;
return 0; }
223 * p_out = p_source [ 0 ];
228 PFC_STATIC_ASSERT(
sizeof(
wchar_t ) ==
sizeof( char16_t ) ||
sizeof(
wchar_t ) ==
sizeof(
unsigned ) );
229 if (
sizeof(
wchar_t ) ==
sizeof( char16_t ) ) {
255 for(;count && ptr[num];count--)
266 while(walk < max && param[walk] != 0) {
270 if (d==0)
return false;
284 if (*param<0)
return false;
297 unsigned rv = 0 , ptr = 0;
304 if (delta>maxbytes || delta==0)
break;
307 out[ptr++] = *(src++);
324 if (w==0 || d<=0)
break;
t_size utf16_encode_char(unsigned c, char16_t *out)
t_size skip_utf8_chars(const char *ptr, t_size count)
t_size strcpy_utf8_truncate(const char *src, char *out, t_size maxbytes)
t_size utf8_encode_char(unsigned c, char *out)
t_size wide_decode_char(const wchar_t *p_source, unsigned *p_out, t_size p_source_length=~0)
static const t_uint8 mask_tab[6]
unsigned utf8_get_char(const char *src)
t_size utf8_char_len_from_header(char c)
t_size strlen_utf8(const char *s, t_size num=~0)
static const t_uint8 val_tab[6]
t_size utf16_decode_char(const char16_t *p_source, unsigned *p_out, t_size p_source_length=~0)
t_size utf8_decode_char(const char *src, unsigned &out, t_size src_bytes)
bool is_valid_utf8(const char *param, t_size max=~0)
t_size wide_encode_char(unsigned c, wchar_t *out)
static bool check_end_of_string(const char *ptr)
t_size utf8_chars_to_bytes(const char *string, t_size count)
t_size utf8_char_len(const char *s, t_size max=~0)
bool is_lower_ascii(const char *param)
 1.8.9.1
1.8.9.1